AI-utbildning
En halvdagsutbildning i praktisk AI-användning — från grunderna till avancerade agenter — anpassad för juridisk verksamhet.
Format: Fritt samtal, live-demos och gemensam utforskning. Ingen traditionell presentation — den här sidan fungerar som vårt manus och referensmaterial efteråt.
Syfte: Ge en solid förståelse för vad AI kan (och inte kan) göra idag, hur man använder verktygen säkert, och vilka konkreta steg byrån kan ta härnäst.
Utvecklingstakten — hur snabbt går det?
Mycket av debatten om AI verkar förvirrad mellan "vad är möjligt idag" och "vad är möjligt i morgon". Svaren är radikalt olika — och glappet mellan dem krymper snabbare än de flesta inser.
"The majority of the ruff ruff is people who look at the current point and people who look at the current slope."— Andrej Karpathy, jan 2026 (fd AI-chef Tesla, medgrundare OpenAI)
Tidslinje
- 2017 — Google publicerar "Attention is All You Need", den artikel som introducerar Transformer-arkitekturen. 8 år sedan.
- 2022 (nov) — ChatGPT lanseras. 1 miljon användare på 5 dagar — snabbast någonsin. Idag: 900 miljoner aktiva användare per vecka (feb 2026).
- 2023 (mar) — GPT-4 lanseras och klarar juristexamen (Uniform Bar Exam, topp 10%) och läkarexamen (USMLE, 86% rätt vs 60% för godkänt). Tidigare modeller underkändes på båda.
- 2024 (sep) — OpenAI släpper o1, första "reasoning"-modellen. Löser bl.a. strawberry-problemet — tidigare modeller kunde inte räkna bokstäver i ord ("hur många r i strawberry?"). OpenAI-forumtråd
- 2025–2026 — AI löser Erdős-problem som stått olösta i 30+ år. GPT-5.2 + verktyget Aristotle knäcker problem #728 autonomt på timmar. Scientific American
METR — Task Time Horizons
METR (Model Evaluation & Threat Research) mäter hur långa uppgifter AI kan lösa. Deras "time horizon" visar den uppgiftslängd (mätt i hur lång tid en mänsklig expert behöver) där AI lyckas 50% av gångerna.
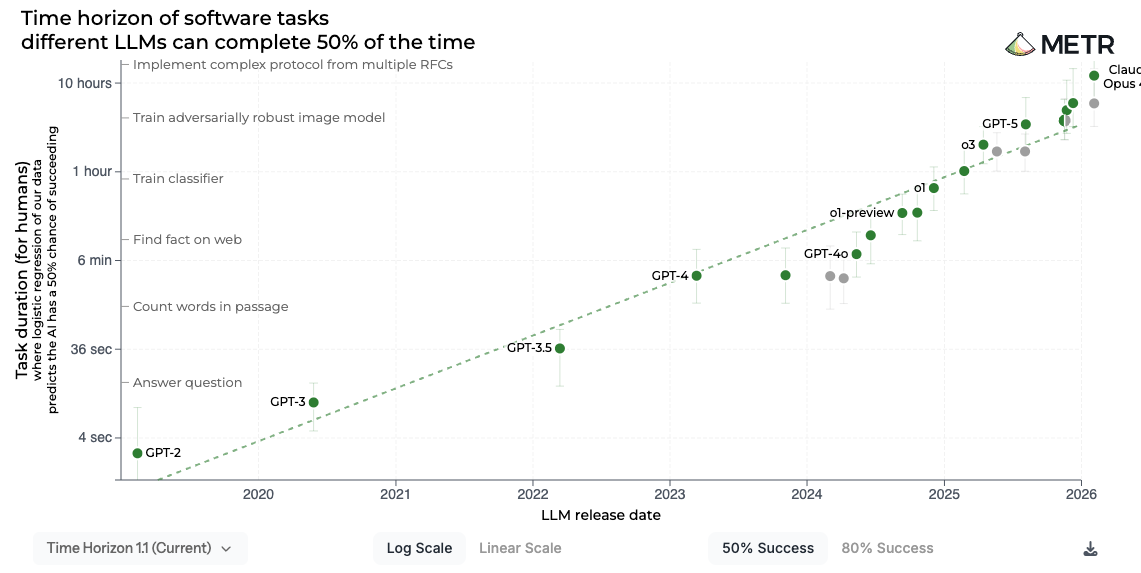
Nyckelinsikt: Uppgiftslängden som AI klarar fördubblas ungefär var fjärde månad. Från sekunder (2019) till timmar (2026). Trenden visar inga tecken på att plana ut.
GDPval — Ekonomisk kapacitet
OpenAIs GDPval-benchmark mäter hur väl AI-modeller presterar på riktiga yrkesuppgifter jämfört med branschexperter. Notera att "Lawyers" finns som en av de testade yrkesgrupperna.
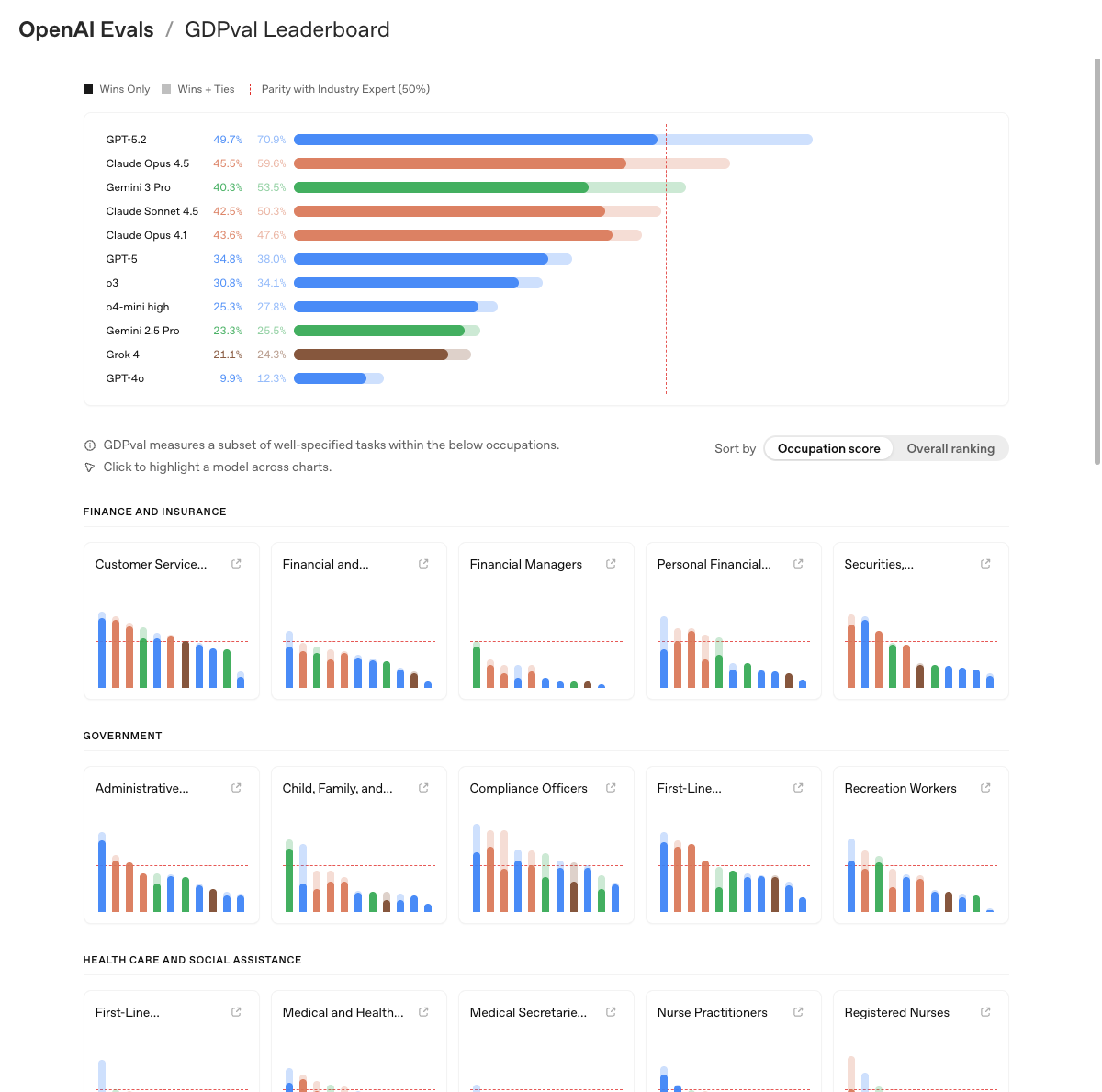
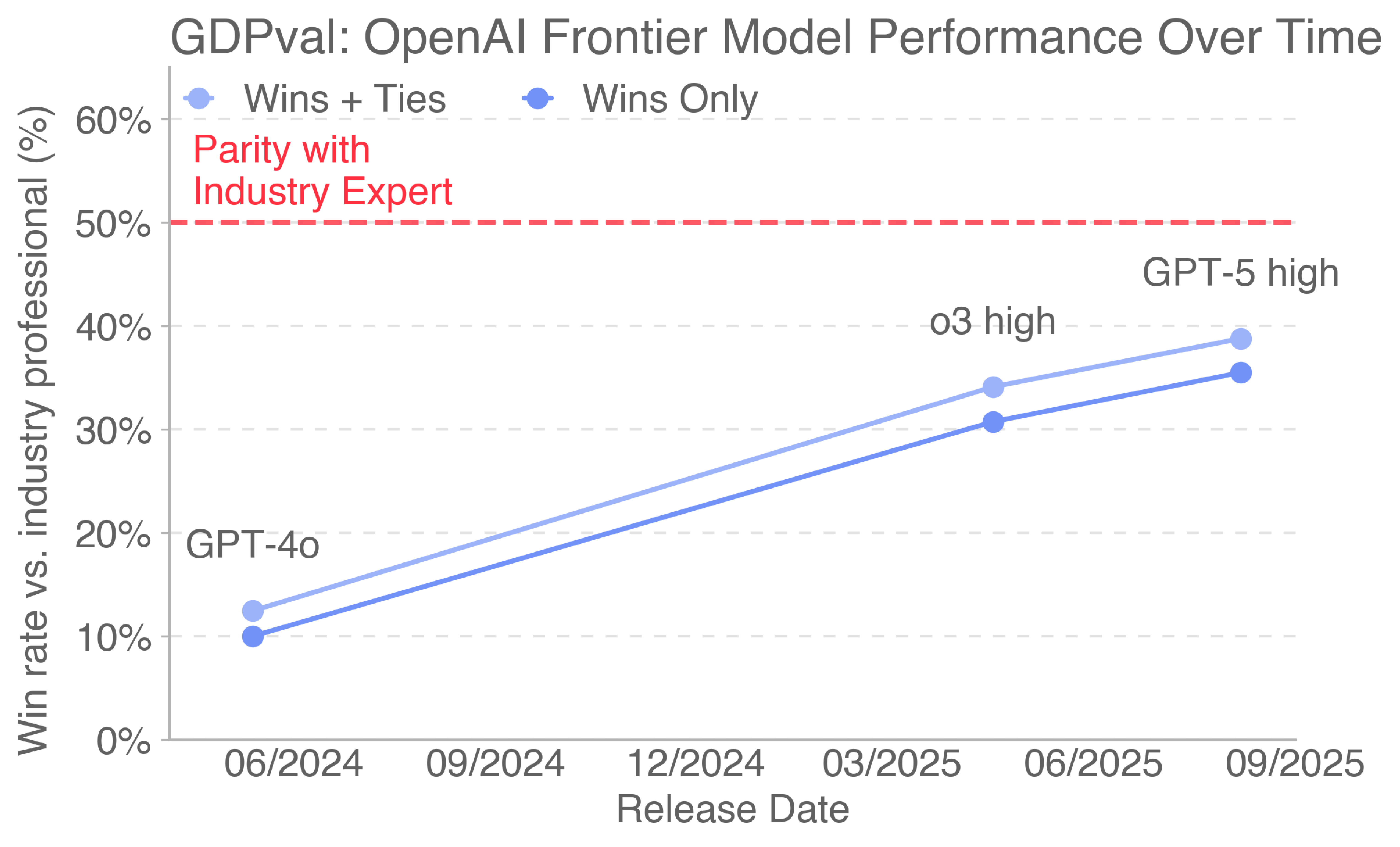
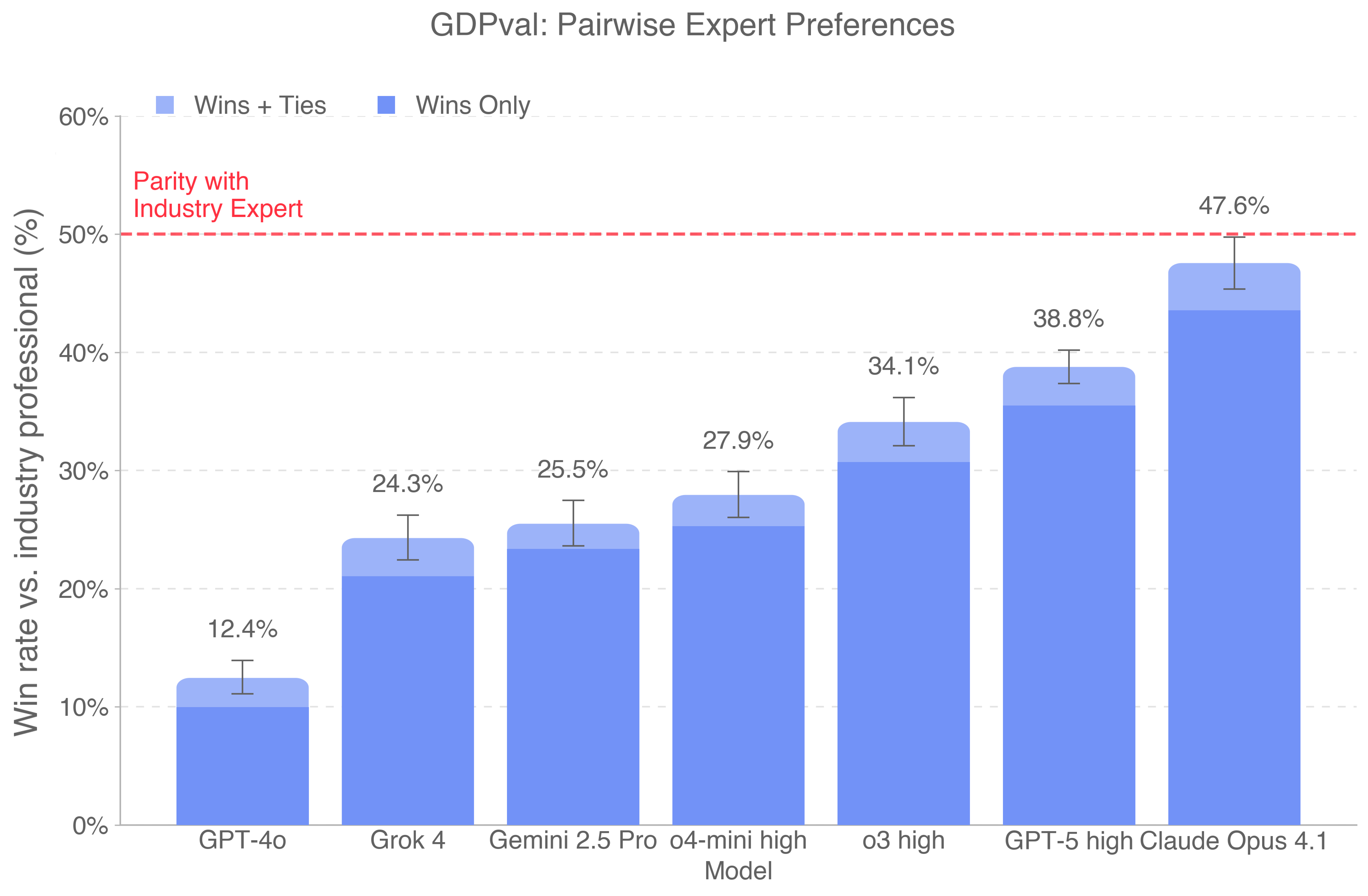
Den ojämna frontlinjen
Ethan Mollick (Wharton) myntar begreppet "the jagged frontier" — AI är inte jämnt bra på allt. Den kan lösa svåra uppgifter men misslyckas med till synes enkla. Gränsen är ojämn och svår att förutsäga.
"Jag vill tvätta bilen. Biltvätten är 50 meter från mitt hus — ska jag gå dit eller ta bilen?"
En modell svarar troligtvis på frågan rakt av. Men den borde ifrågasätta premissen — varför inte bara köra bilen dit, den ska ju ändå tvättas? AI kan lösa svåra problem men missa det uppenbara.
Sammanfattning: Ändringstakten är extremt hög. Nya förmågor tillkommer snabbt, men luckor och begränsningar finns fortfarande. Det som inte fungerar idag kan fungera om 3 månader.
Datasäkerhet
En avgörande fråga för en advokatbyrå: vad händer med datan jag matar in?
Konsument vs Business vs Enterprise
| Nivå | Träning på din data? | Datalagring | Typiskt pris |
|---|---|---|---|
| Gratis (ChatGPT, Claude) | Ja, som standard | Varierar — kan vara långvarig | 0 kr |
| Individuellt betalt (Plus/Pro/Max) | Ja, som standard — kan stängas av | Varierar per tjänst och inställning | ~200–2 000 kr/mån |
| Team / Business | Nej som standard | Begränsad, styrs av admin | ~250–500 kr/anv/mån |
| Enterprise / API | Nej | Enligt avtal och konfiguration | Varierar |
Viktigt: Att betala för en individuell plan (ChatGPT Plus, Claude Pro) innebär inte att din data automatiskt skyddas från träning. Båda företagen behandlar individuella betalplaner som konsumentprodukter — träning är på som standard och måste stängas av manuellt. Först på Team/Business-nivå gäller kommersiella villkor där data inte används för träning.
ChatGPT vs Claude — policyskillnader
- OpenAI (ChatGPT): Free, Plus och Pro (personlig workspace) kan användas för modellförbättring som standard — användaren kan stänga av det i Data Controls. Business och Enterprise: data används inte för träning. Data kan lagras för missbrukskontroll (retention varierar beroende på plan och konfiguration).
- Anthropic (Claude): Konsumentplaner (Free, Pro, Max) omfattas av konsumentpolicyn — användning för träning beror på användarens privacy-inställningar och är på som standard. Kommersiella produkter (Team, API, Bedrock, Vertex) omfattas av kommersiella villkor där data inte används för träning.
- Var hanteras data? Båda företagen lagrar data primärt i USA för konsumenttjänster. EU-dataresidency finns som alternativ för enterprise-kunder hos båda (OpenAI via Enterprise/Edu, Anthropic via Bedrock/Vertex), men inte för konsumentplaner.
Lokala modeller som alternativ
- Ollama, LM Studio, llama.cpp — kör open source-modeller (Llama, Mistral, Qwen) lokalt på din dator.
- All data stannar på maskinen. Inget skickas till molnet.
- Nackdel: Lägre kapacitet än de bästa molnmodellerna. Kräver kraftig hårdvara för bra resultat.
- Bra komplement för känsliga ärenden, inte ersättning för allt.
Rekommendation för advokatbyrå: Använd alltid Team/Business eller Enterprise — inte individuella planer (Plus/Pro). Mata aldrig in klientidentifierande uppgifter i konsumentverktyg. Överväg lokala modeller för särskilt känsliga ärenden. Etablera en intern policy som specificerar vilka planer och inställningar som är godkända.
Hur fungerar en LLM?
Träning — bygga modellen
- Data: Enorma mängder text — böcker, webbsidor, kod, vetenskapliga artiklar. GPT-4 tränades på uppskattningsvis 13 biljoner tokens — det motsvarar ungefär 100 miljoner böcker, eller allt som mänskligheten någonsin skrivit, flera gånger om.
- Kostnad: Hundratals miljoner dollar i beräkningskraft. Tusentals GPU:er (specialiserade grafikkortschip, ursprungligen gjorda för spel, nu hjärtat i AI-beräkningar) i månader.
- Resultat: En modell som lärt sig statistiska mönster i språk — inte "kunskap" i mänsklig mening, utan extremt sofistikerad mönsterigenkänning.
Inferens — använda modellen
- När du chattar med Claude eller ChatGPT skickas din text till servrar som kör modellen.
- Modellen genererar svar token för token (ungefär ord för ord), baserat på sannolikheter.
- Varje svar är stokastiskt — samma fråga kan ge olika svar varje gång.
Grundbegrepp
| Begrepp | Förklaring |
|---|---|
| Token | Minsta enheten modellen arbetar med. Ungefär ¾ av ett ord på engelska. "Advokatbyrå" ≈ 3–4 tokens. |
| Kontextfönster | Hur mycket text modellen kan "se" samtidigt. Tänk det som arbetsminne. Claude Opus: 200k tokens ≈ 600 sidor text ≈ ett par romaner. Gemini: 2M tokens ≈ hela Harry Potter-serien tre gånger. Gemini kan även ta in video (ca 2 timmar) och ljud direkt. |
| Temperatur | Styr hur "kreativ" vs "förutsägbar" modellen är. Låg = mer deterministiskt. Hög = mer variation. |
| Hallucination | När modellen genererar text som låter korrekt men är påhittad. Ett grundläggande problem, inte en bugg. |
Vad är lätt respektive svårt för AI?
| Lätt | Svårt |
|---|---|
| Sammanfatta text | Exakta siffror och beräkningar utan kontroll |
| Översätta mellan språk | Referera till specifika rättsfall korrekt |
| Skriva utkast och mallar | Garantera att inget missas |
| Förklara juridiska begrepp | Avancerad dokumentformatering och layout |
| Analysera kontrakt | Hantera bilder i dokument |
| Brainstorma och strukturera | Produktionsklar datavisualisering |
Modell vs verktyg — förvirrande nomenklatur
"Modell" = den underliggande AI-motorn (GPT-5.2, Claude Opus 4.6, Gemini 3).
"Verktyg" = appen eller gränssnittet du använder (ChatGPT, Claude.ai, CoPilot, Gemini-appen).
Gränserna suddas ut: CoPilot (Microsoft) kan idag använda både GPT-modeller och Claude under huven. Samma verktyg kan alltså byta eller kombinera modeller över tid. Men ChatGPT-appen erbjuder bara OpenAI:s egna modeller, och Claude.ai bara Anthropics.
Hands on med verktygen
Vi testar ChatGPT och Claude live. Fokuspunkter:
Gemensamma koncept
- Modellval: Olika modeller för olika uppgifter. Snabbare modeller för enkla frågor, kraftfullare för analys.
- Tillfällig/inkognito-chatt: Både ChatGPT och Claude erbjuder lägen där konversationen inte sparas.
- Minne och kontext: Verktygen kan "komma ihåg" saker mellan sessioner — men det kräver aktiv hantering.
ChatGPT-specifikt
- Custom Instructions: Berätta för ChatGPT vem du är och hur du vill ha svar.
- GPTs: Specialanpassade versioner av ChatGPT för specifika uppgifter.
- Deep Research: ChatGPTs verktyg för att söka igenom webben systematiskt och sammanställa en rapport.
- Memory: ChatGPT minns saker du berättat i tidigare konversationer.
Claude-specifikt
- Projects: Samla filer, instruktioner och konversationer i ett projekt.
- Artifacts: Claude skapar dokument, kod och annat direkt i konversationen — redigerbart i realtid.
- Company Knowledge: (Enterprise) Koppla Claude till företagets befintliga dokument så att den kan söka och referera till intern kunskap.
- Custom Instructions: Samma koncept som ChatGPT — berätta hur du vill ha svar.
Live-demo
Vi öppnar ChatGPT och Claude sida vid sida och testar samma uppgift i båda. Jämför svarskvalitet, ton och hantering av uppföljningsfrågor.
Prompting — grunderna
Hur du formulerar din fråga avgör kvaliteten på svaret. Några principer:
1. Ge tillräckligt med kontext
Ju mer relevant bakgrund du ger, desto bättre svar. Berätta vem du är, vad du arbetar med, och vad du ska använda svaret till.
2. Var specifik med vad "bra" betyder
Ge exempel på vad du förväntar dig. Few-shot examples — visa 1–2 exempel på önskat format innan du ställer den riktiga frågan.
3. Hantera hallucinationer
- Be modellen citera sina källor
- Be den flagga osäkerhet: "Om du är osäker, säg det."
- Dubbelkolla alltid fakta, rättsfall och siffror
- "Check your output" — be modellen granska sitt eget svar
4. Använd modellen som tankeverktyg
- "Vilka komplikationer kan uppstå?"
- "Vad borde jag fråga mer om?"
- "Debattera mot dig själv — ge argument för och emot"
5. Ange målgrupp
Berätta vem svaret är till: "Förklara som för en klient utan juridisk bakgrund" vs "Skriv ett PM till en kollega-advokat".
6. "Intervjua mig"
Istället för att försöka formulera den perfekta prompten på en gång — be modellen ställa frågor till dig: "Intervjua mig om det här ärendet tills du har tillräcklig kontext för att skriva ett utkast." Fungerar också som kvalitetskontroll: "Ställ frågor om något är oklart innan du börjar."
7. Låt AI:n förbättra din prompt
Om du inte får det resultat du vill ha — be modellen hjälpa dig formulera om. Exempelvis: "Jag skrev den här prompten X och förväntade mig Y, men fick Z istället. Hjälp mig förbättra prompten." AI är ofta bättre på att skriva promptar än vi är.
8. Braindump
Dumpa allt du vet om ett ämne — ostrukturerat, röstmeddelanden, bilder — och be modellen strukturera det. AI är utmärkt på att hitta struktur i kaos.
Live-demo
Vi testar: samma juridiska fråga med en vag prompt vs en välformulerad prompt. Jämför resultaten.
Agenter
Moderna AI-verktyg innehåller allt mer agentiska funktioner — modellen svarar inte bara, utan kan planera, ta steg och använda verktyg mer självständigt.
Chatt vs agentiskt arbetssätt
- Chatt: Du ställer en fråga → AI svarar. En interaktion i taget.
- Agentiskt: Du ger ett mål → AI planerar flera steg, använder verktyg, hämtar information och utför delar av arbetet självständigt.
Gränsen är flytande — ChatGPT:s "agent mode" och Claudes projektfunktioner är exempel på hur agentiska förmågor byggs in i chattverktygen.
Vanliga agentförmågor
- Verktygsanvändning: Söka i databaser, skriva dokument, skicka mail, köra kod.
- Filhantering: Läsa, skriva och bearbeta filer — inte bara text i ett chattfönster.
- Stegvis informationshämtning: Kan hämta mer data under arbetets gång när uppgiften kräver det.
- Minne och kontext: Vissa verktyg erbjuder persistent kontext mellan sessioner, men graden varierar mycket mellan produkter.
Exempel på agentverktyg
| Verktyg | Vad det gör |
|---|---|
| ChatGPT agent mode | Agentiskt läge inbyggt i ChatGPT — kan söka, köra kod, navigera webb och utföra flerstegsuppgifter |
| Claude Code | Agentiskt kodverktyg i terminalen — skriver, kör och felsöker kod, hanterar filer och projekt |
| Claude Cowork | Agenter som arbetar med företagsdata, e-post och dokument i Claudes gränssnitt |
| OpenAI Codex | Kodningsagent i molnet — liknande Claude Code men i OpenAI:s ekosystem |
Landskapet förändras snabbt — nya funktioner och verktyg tillkommer löpande.
Begränsningar och risker
- Fel i flera led: Agenter gör misstag — och misstagen kan vara svårare att upptäcka när de agerar självständigt över flera steg.
- Kontextfönster: Fortfarande begränsande vid stora dokumentmängder — agenten kan inte läsa allt på en gång.
- Hallucinationer vid skala: Ju fler dokument, desto högre risk att information förväxlas eller fabriceras.
- Mänsklig granskning krävs: En människa bör alltid granska agentens arbete, särskilt i juridiska sammanhang.
Hands on: Arbetsredogörelse med AI
Vi arbetar med Guys konkreta uppdrag: att med hjälp av AI sortera en stor mängd dokument och e-post, strukturera materialet kronologiskt, och producera en arbetsredogörelse.
Uppgiften
- ~4 500 filer och lika många mejl som underlag
- Dokumenten ska sorteras i tidsordning
- Sammanställas årsvis under relevanta rubriker
- Slutligen skrivas ihop till en sammanhängande rapport
Arbetsgång — steg för steg
- Inventera och rensa: Låt AI:n scanna katalogen och kategorisera allt: filtyp, storlek, läsbarhet. Identifiera dubbletter, oläsbara filer och format som behöver konverteras innan man börjar.
- Indexera: Bygg ett index över alla läsbara filer — filnamn, datum, typ, kort sammanfattning. Resultatet skrivs till en fil på disk.
- Strukturera: Utifrån indexet — gruppera per år och ämnesområde. Låt AI:n föreslå rubriker baserat på innehållet.
- Sammanfatta per period: AI:n läser dokumenten inom varje grupp och skriver sammanfattningar. Granska och justera — AI:n missar nyanser, du fångar dem.
- Skriv rapporten: Använd sammanfattningarna som underlag. Låt AI:n skriva ett första utkast. Iterera tills ton, struktur och innehåll stämmer.
Förbehandling — vad kan gå fel?
4 500 filer från en verklig ärendehantering är sällan rena och enhetliga. Räkna med att behöva hantera:
- Dubbletter: Samma dokument sparat flera gånger, som bilaga i mejl och som separat fil, i olika versioner. Deduplicering tidigt sparar mycket arbete — annars räknas samma händelse dubbelt i rapporten.
- Oläsbara format: Proprietära filer (.msg, .pst, äldre Word-format, skannade PDF:er utan OCR) kan inte läsas direkt av AI. Behöver konverteras eller OCR-behandlas först.
- Blandade filtyper: PDF, Word, Excel, e-post, bilder, skanningar — varje typ kräver olika hantering. AI kan sortera dem, men du behöver verktyg för konvertering (t.ex. pandoc, tesseract för OCR).
- Inkonsistenta datum: Filnamn säger en sak, filens metadata en annan, och texten i dokumentet en tredje. Definiera tidigt vilken datumkälla som gäller.
- Tomma eller korrupta filer: Förekommer alltid i stora samlingar. Bättre att flagga dem tidigt än att upptäcka luckor i slutet.
Hur kommer AI:n åt filerna?
En avgörande fråga: filerna ligger lokalt på datorn. Olika verktyg har olika åtkomstmodeller.
| Verktyg | Filåtkomst | Hur det fungerar |
|---|---|---|
| Claude Cowork | Lokal mapp | Desktop-app — du pekar på en katalog, agenten läser filerna direkt. Inget behöver laddas upp. Data stannar lokalt. |
| Claude Code | Lokal mapp | CLI-verktyg — kör direkt i katalogen i terminalen. Kan skriva skript som automatiserar sortering. Finns för macOS, Linux och Windows (native, kräver inte WSL). |
| OpenAI Codex CLI | Lokal mapp | Liknande Claude Code — kör lokalt i terminalen med direkt filåtkomst. |
| ChatGPT | Molndrive eller uppladdning | Kan kopplas till Google Drive och SharePoint via "apps with sync". Ingen lokal filåtkomst. Agent mode kan inte använda drive-kopplingarna — bara vanlig chatt och deep research kan det. |
För 4 500 lokala filer är Cowork eller Claude Code de praktiska alternativen. ChatGPT funkar om filerna redan ligger på Google Drive eller SharePoint, men inte för lokala filer.
Hur hanterar man att allt inte ryms i kontextfönstret?
Kontextfönstret (arbetsminnet) rymmer inte allt material på en gång. Nyckeln är att skriva mellanresultat till disk — AI:n behöver inte hålla allt i huvudet samtidigt.
- Claude Code / Cowork: Agenten hanterar batchningen själv. Den kan skriva ett skript som läser alla 4 500 filer, extraherar metadata, och sparar ett strukturerat index till en fil. Sedan arbetar den vidare utifrån indexet. Du behöver inte dela upp manuellt.
- ChatGPT: Mer handpåläggning krävs. Du laddar upp dokument i omgångar, sammanfattar varje omgång, och bygger ihop resultatet stegvis.
Principen: Tänk som ett riktigt kontorsjobb. Ingen läser 4 500 dokument i ett svep — man bygger ett register, sorterar i högar, sammanfattar per hög, och skriver rapporten utifrån sammanfattningarna. AI arbetar på samma sätt, men snabbare.
Viktigt vid känsligt material: Bedöm vilka dokument som kan skickas till molntjänster och vilka som bör hanteras lokalt. Se datasäkerhetssektionen ovan.
Vanliga fallgropar
- Datumtolkning: AI kan misstolka datum i äldre dokument, skannade filer och blandade format. Stickprovskontrollera.
- Hallucinerade kopplingar: AI kan fabricera samband mellan dokument som inte finns. Verifiera kronologin mot källmaterialet.
- "Komplett" betyder det inte: AI kan missa dokument eller perioder utan att flagga det. Räkna filerna — stäm av att indexet täcker allt.
Live-demo
Vi testar hela flödet med ett urval av dokumenten: inventering → indexering → strukturering → sammanfattning → rapportutkast.
Nästa steg
Sammanfattning
- AI utvecklas exponentiellt — det som inte fungerar idag kan fungera inom månader.
- Datasäkerhet kräver medvetna val: betald tjänst, intern policy, rätt verktyg för rätt uppgift.
- Promptkvalitet är avgörande — kontext, specificitet och uppföljning gör hela skillnaden.
- Agenter är nästa steg — men kräver fortfarande mänsklig övervakning.
- AI är ett tankeverktyg, inte en ersättare för juridiskt omdöme.
Konkreta steg för byrån
- Välj verktyg: Skaffa betald Claude- eller ChatGPT-prenumeration (Team-plan).
- Skriv intern policy: Vad får matas in? Vilka typer av ärenden kräver extra försiktighet?
- Börja smått: Använd AI för sammanfattningar, utkast, och research — inte som ensam källa.
- Bygg kompetens: Experimentera regelbundet. Prompting är en färdighet som utvecklas med övning.
- Följ utvecklingen: Nya modeller och verktyg lanseras löpande. Utvärdera kvartalsvis.
Resurser
- METR Time Horizons — uppföljning av AI-kapacitet
- GDPval Leaderboard — AI på yrkesuppgifter
- Ethan Mollick — One Useful Thing — utmärkt blogg om AI i praktiken
- ChatGPT · Claude — de två verktygen vi använt idag
Magnus Gille · Magnus Gille Consulting AB
magnus@gille.ai · gille.ai